Ravi Kanani
Founder & Cloud Cost Optimization Consultant
I help startups and scaleups cut cloud costs by 30-60% across AWS, GCP, and Azure. With hands-on experience optimizing infrastructure for companies from Series A to Series C, I focus on delivering measurable savings through FinOps, Kubernetes optimization, and infrastructure modernization, not slide decks or dashboards.
Areas of Expertise
Deep specialized expertise across the entire modern cloud and DevOps stack.
Cloud Cost Optimization
30-60% reduction in AWS, Azure, and GCP spend
FinOps & Cloud Financial Management
Budgeting, forecasting, and cost governance
Kubernetes Optimization
Rightsizing, Karpenter, and Spot instance strategies
Infrastructure Modernization
Migration from legacy to cloud-native architecture
Multi-Cloud Strategy
TCO analysis and workload placement optimization
DevOps & Automation
CI/CD, IaC, and operational efficiency
Recent Articles
View All
Cost anomaly detection is the easiest FinOps capability to deploy and the hardest to deploy correctly. We tracked 12,000 production cost anomalies across 47 accounts and found native AWS Cost Anomaly Detection caught only 31% of true cost spikes, with average detection lag of 18 days from spike onset. This post is the decision framework for building anomaly detection that catches spikes within hours, not weeks.
Traditional FinOps practices were built around predictable cloud workloads (EC2, RDS, S3) that scale linearly with users. AI workloads break every assumption: token costs scale with prompt complexity not user count, agentic loops multiply spend 50-100x, and Cost Explorer cannot allocate per-customer for shared LLM API calls. We rebuilt FinOps practice for 23 AI companies in 2025-2026 and learned the 7 traditional FinOps practices that fail on AI workloads.

The FinOps Foundation's Crawl/Walk/Run framework is well-known but consistently misapplied. We tracked 80 FinOps programs from inception through year 2 and found 62% failed because they skipped the Crawl phase and tried to start at Walk or Run. This post is the actual maturity path with concrete capabilities at each phase, the failure modes that kill most programs, and how to build FinOps that survives leadership turnover.
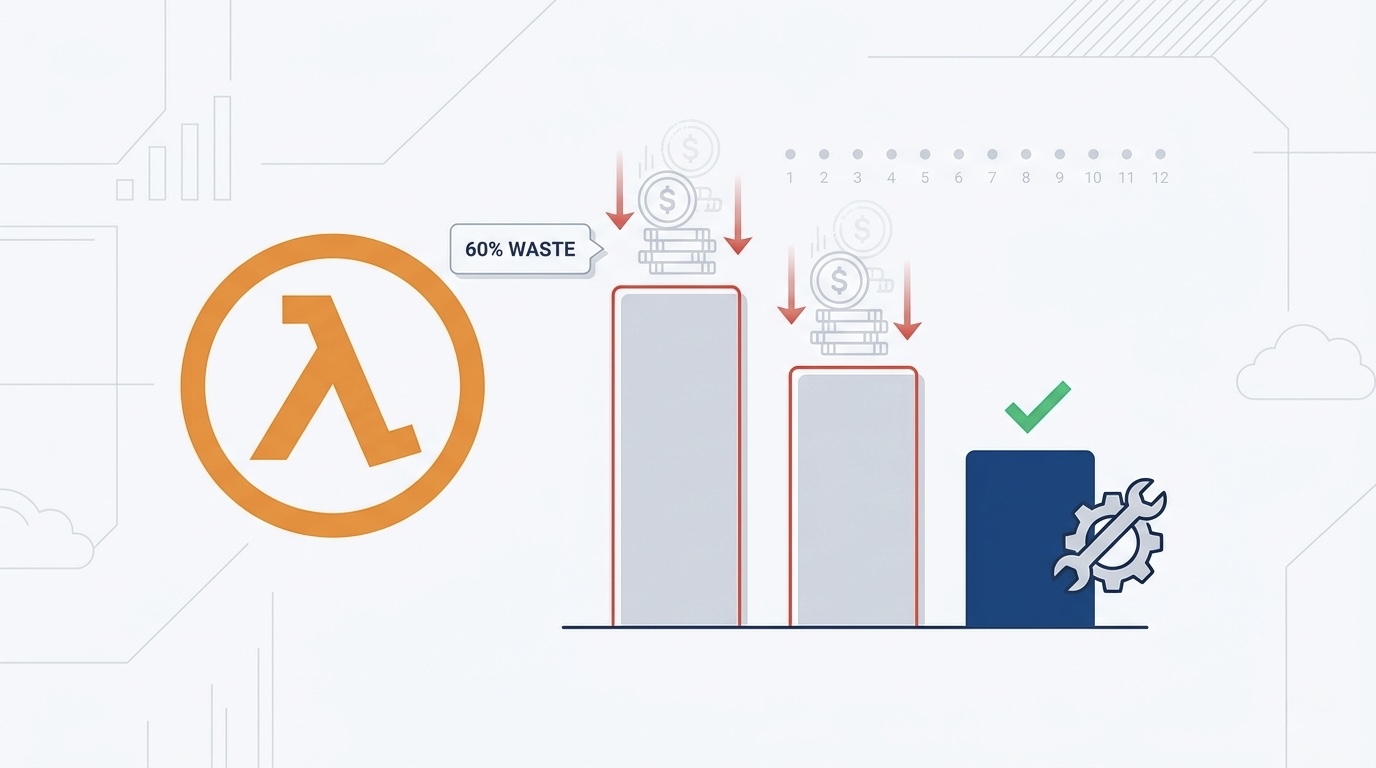
AWS Lambda is the most over-provisioned compute service in 2026 because the pricing model is opaque and most teams set memory and timeout values by guessing. We audited 92 production Lambda accounts and found the average bill was 60% higher than necessary due to 12 specific waste patterns. This is the fix list, with real cost math for each issue.
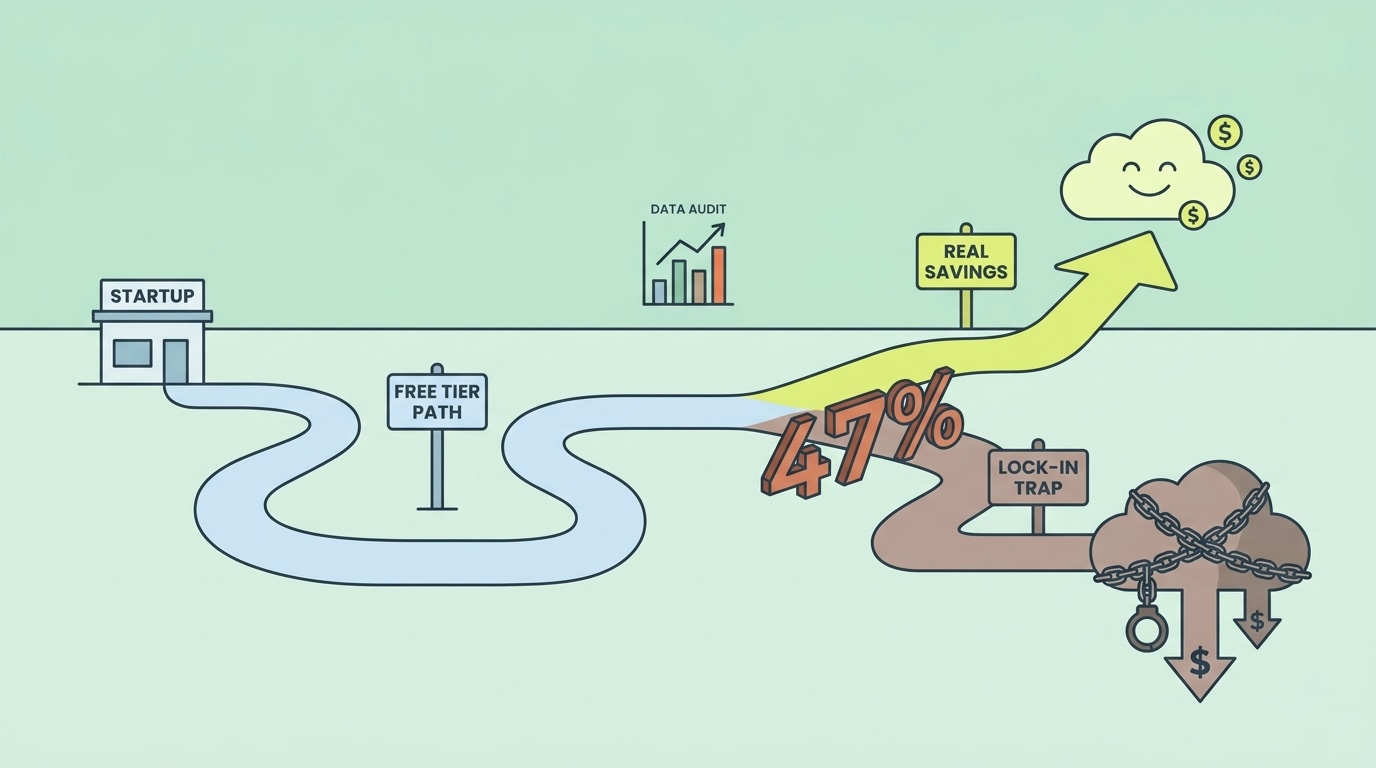
Free tiers are marketed as startup-friendly savings but many trigger expensive lock-in once your usage crosses thresholds. We tracked 200 early-stage companies through their free-tier graduations and found 47% paid more than they would on a different provider once they crossed the free tier cliff. This is the decision framework for picking free tiers that genuinely save money vs ones that capture you.
GCP is often considered cheaper than AWS, but most teams running on Google Cloud overspend by 40-60% because GCP's commitment system, network pricing, and BigQuery slot model are dramatically different from AWS conventions. We audited 38 production GCP accounts in 2025-2026 and found 11 specific cost levers teams consistently miss. This is the fix list with real cost math for each.
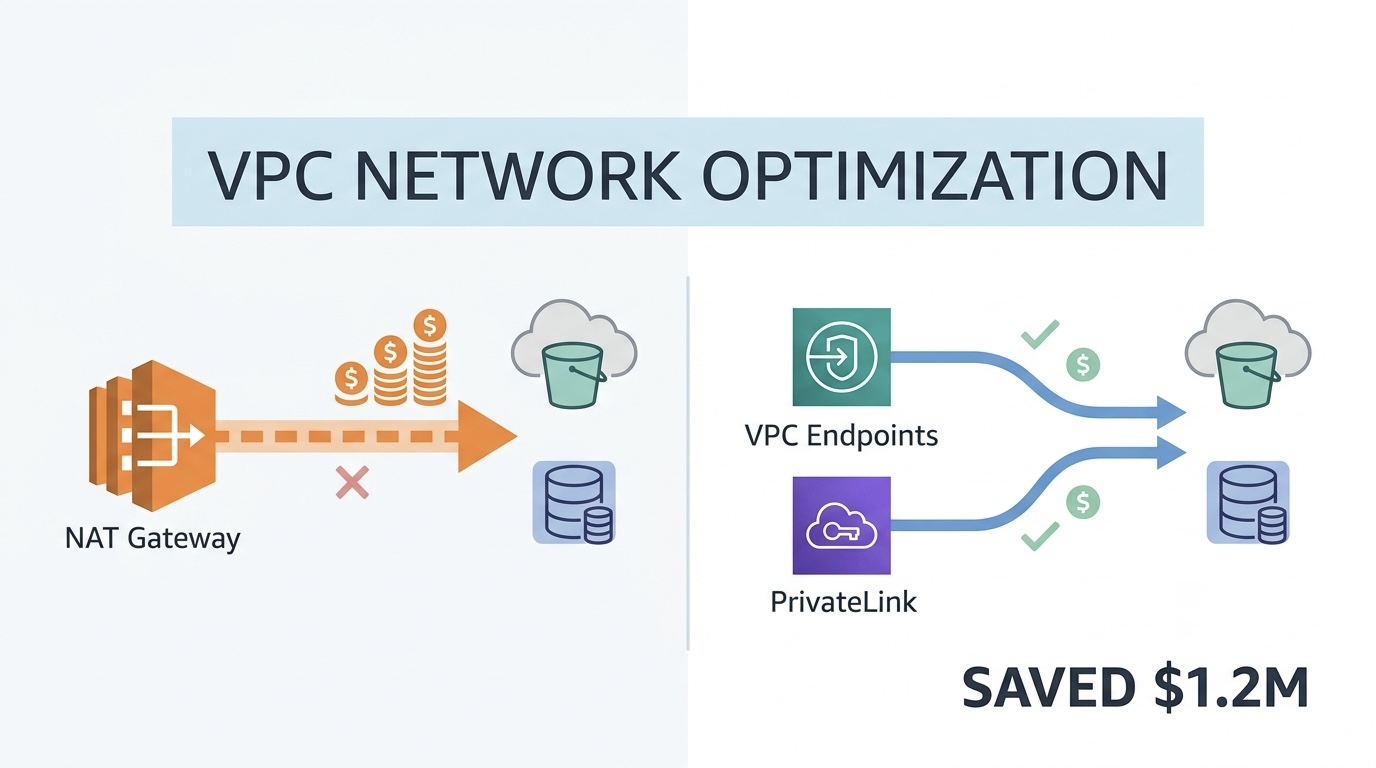
Most AWS architects use NAT Gateways for everything because they did it that way once and it worked. We audited 35 production AWS accounts and found average network costs were 3-4x what they should be due to misuse of NAT Gateway when VPC Endpoints, PrivateLink, or Transit Gateway would cost 80-95% less. This is the architectural decision framework based on real audit findings.
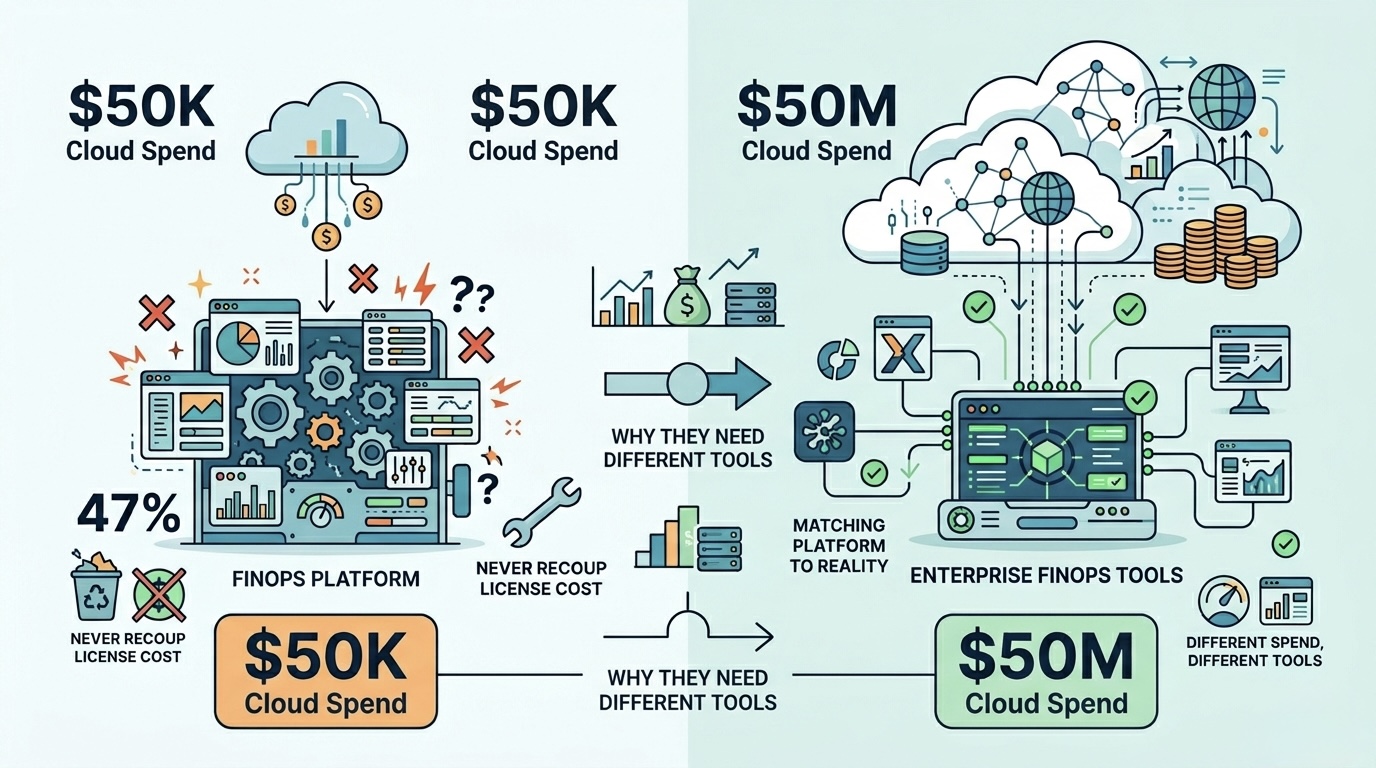
Most 'best FinOps tools' lists rank platforms in absolute terms, ignoring that the right tool depends entirely on your cloud spend tier. We deployed 9 different FinOps platforms across 60+ companies in 2025-2026 and found 47% of tool purchases never recouped their license fee. This is the spend-tier decision framework that matches platform to budget reality.

Most teams pick a video streaming platform once and never benchmark alternatives. We delivered over 4 petabytes of video across Mux, Cloudflare Stream, AWS MediaConvert+CloudFront, and self-hosted FFmpeg+Bunny CDN in 2025-2026 and found the cost spread for identical workloads exceeded 9x. This is the workload-to-platform decision framework based on real production deployments.

Spot instances promise 60-90% savings, but for 41% of workloads we tracked, the interruption recovery cost exceeded the discount. We analyzed 12,000 interruptions across 40 production deployments and found the real Spot economics depend on workload type, instance family choice, and failover architecture. This is the workload-to-Spot decision framework based on actual interruption data.
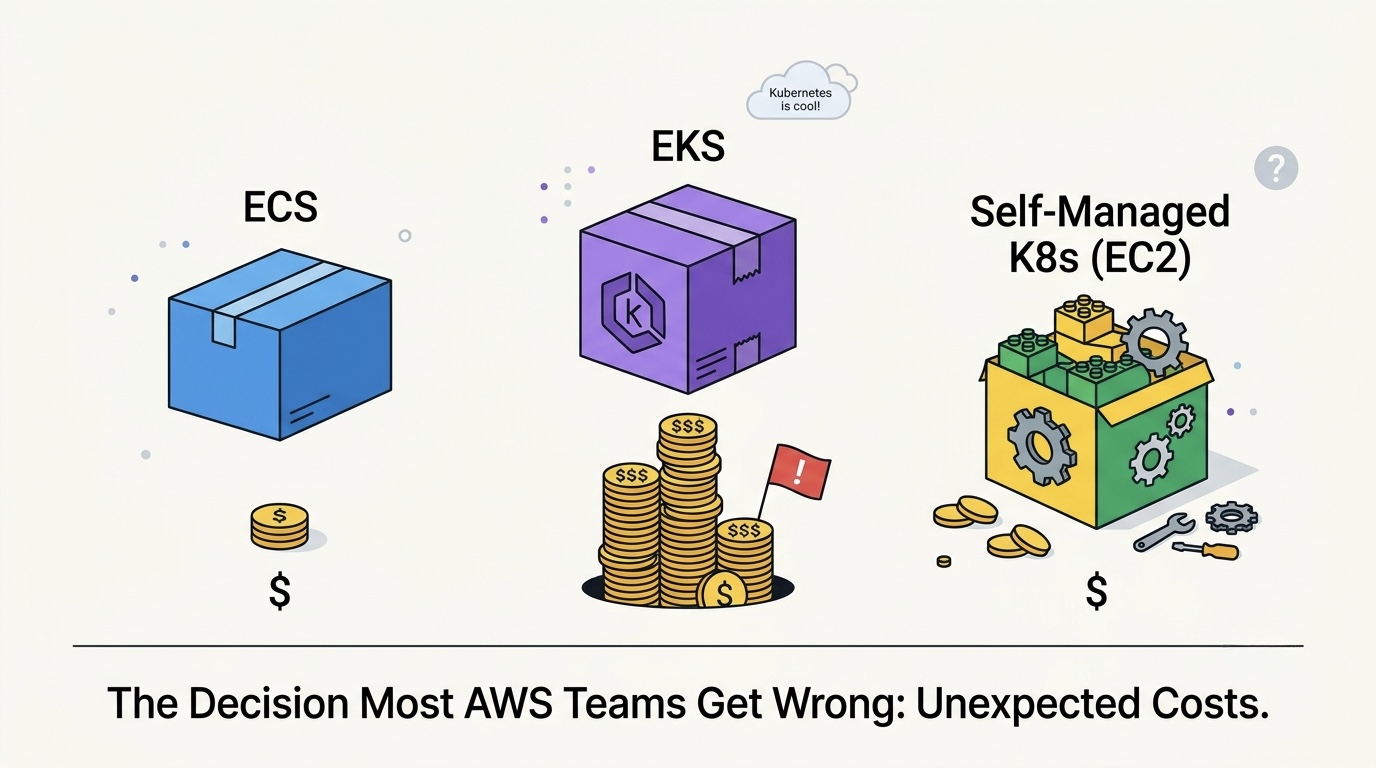
Most AWS teams default to EKS because Kubernetes is the cool answer. We benchmarked 26 production container workloads across ECS, EKS, and self-managed K8s on EC2 and found EKS was the right choice in only 40% of cases. This is the workload-to-orchestrator decision framework based on real production migrations and total cost of ownership analysis.
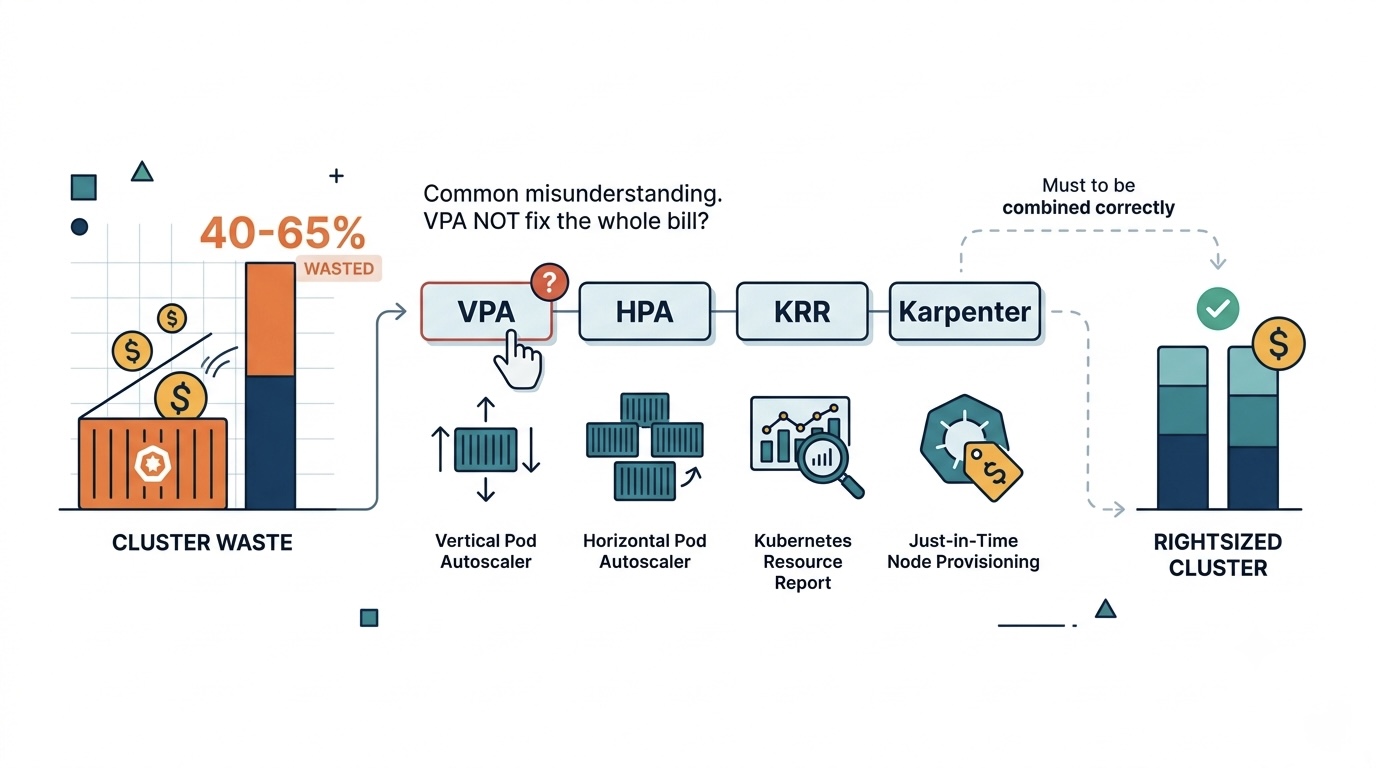
Most teams pick one Kubernetes rightsizing tool and assume it solves the cost problem. We rightsized 80 production clusters in 2025-2026 and found the four major tools (VPA, HPA, KRR, Karpenter) each solve different problems and need to be combined correctly. Picking the wrong tool combination leaves 40-65% of waste in place.
Work With Ravi
Get a free Cloud Waste Assessment and see exactly where your infrastructure spend can be optimized.